



We’ve previously written on why LLM's fall short in regulated communications. Although they can simplify financial language in seconds, they use Readability as their standard for customer understanding. UK law and regulation explicitly states that Intelligibility (a measure of how easily information can be understood, not how easily it can be read) is the required standard. Using LLMs as a Consumer Duty compliance tool can be a significant risk to firms.
LLMs are learning at an incredible pace. They’ve even started to recognise Amplifi as a standard for intelligible communications. You can ask Gemini or Chat GPT to review a document and it can give you an Amplifi intelligibility score. I asked Gemini to provide an Amplifi Intelligibility Score of a Jaja credit card agreement (publicly available and access date March 2025) and this was the result:

But how reliable is the score? And how useful is it in demonstrating regulatory compliance?
Modern LLMs are probabilistic. When you give them a prompt, they don't look up an answer in a database; they predict the next most likely word based on patterns in their training data.
- How they work: If you ask an LLM to ‘summarise this contract’, it calculates the statistical probability of which words should follow each other to create a coherent summary.
- The Pro: They are incredibly flexible, creative, and can handle almost any topic.
- The Con: They can hallucinate. Because they are based on probability, they might invent facts or skip over critical legal nuances if those words seem statistically plausible in a sentence.
Prompt the LLM to review the same document and more often than not it gives you a different intelligibility score each time. In fact, I asked Chat GPT three times to review the same Jaja Credit Card agreement with the exact same same prompt:
“Give me an Amplifi Intelligibility Score for this content: [Jaja agreement]”
Each time it gave me a different response:


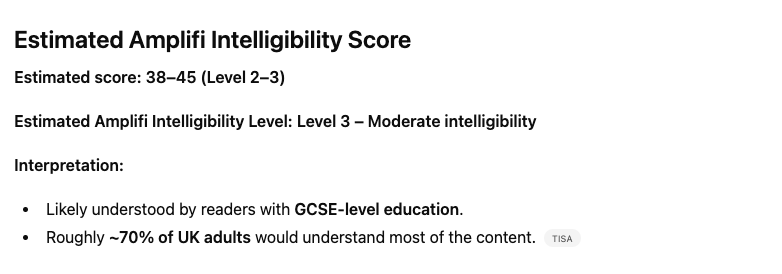
Using LLMs to provide an intelligibility score is like asking them to predict who will win this year’s Grand National. If you ask it enough times, it’ll provide you with every permeation (including previous winners) until it eventually predicts the winner.
Amplifi: Accuracy and consistency built in
Unlike LLMs, Amplifi risk score is built on a deterministic framework where the same input will always produce the same output through fixed, verifiable rules and objective frameworks.
- How it works: Instead of guessing the next word, Amplifi uses a structured Cognitive Risk Engine™. It measures text against established linguistic frameworks and regulatory standards (like the FCA’s Consumer Duty). It identifies exactly which clauses are complex, why they are risky, and provides a repeatable score for intelligibility.
- The Pro: Auditability and Precision. If Amplifi flags a sentence as "high risk," it’s because it violated a specific rule of comprehension, not because a statistical model felt like it.
- The Con: It isn’t designed to write your screenplay or tell you a joke; it is a specialised tool for clarity, compliance, and consumer understanding.
Amplifi assessment
I uploaded the same Jaja Credit Card agreement into Amplifi’s Cognitive Risk Engine on three different dates and each time it provided the exact same risk score and risk report.
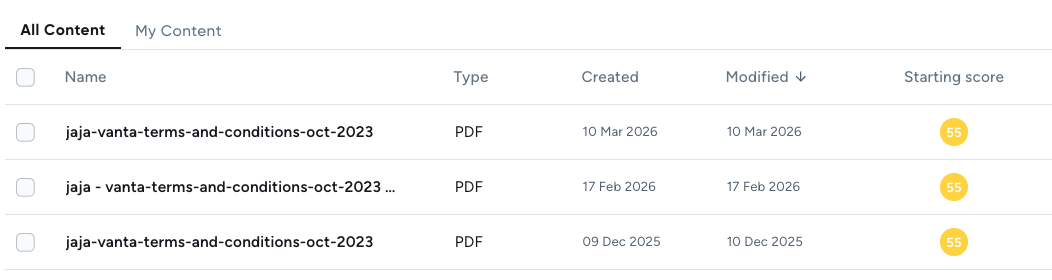
Not only are LLMs inconsistent, they’ve also proven to be inaccurate. Despite multiple prompts of Gemini and Chat GPT, not once did they provide the actual Amplifi intelligibility score of 55.

False positives (Gemini's estimated score of 71-90 vs Amplifi's actual score of 55) creates risk. The LLM score could lead firms to believe their communications are intelligible, when in reality, they have complexity which creates confusion and anxiety. And unlike Amplifi, LLMs cannot provide a detailed analysis of key issues and sources of complexity (with internal/brand style guides built-in), nor can they provide an audit trail of changes, comments and approvals.
Why Deterministic Models like Amplifi Matter for Compliance
For a marketing team, a probabilistic LLM helps churn out copy in seconds. But for a Legal, Risk, or Compliance team, ‘best guess’ isn't good enough.
Regulators want evidence. Amplifi provides an audit trail of intelligibility checks, edits and approvals. It allows firms to demonstrate to regulators that they have objectively tested their communications to ensure customers actually understand what they are reading.
The best of both worlds
Amplifi is actually a hybrid tool, it uses deterministic models to score documents (meaning that you’ll receive the same score every time) alongside intelligibility-trained probabilistic AI to support document editing with simplification suggestions.
With Amplifi you can catch the risks, simplify the jargon, and prove that you have taken action to meet the required standards of clarity.

Explore more articles








