
Systems-Level Limitations of Copilot for Task-Based Text Simplification


In regulated markets, simplification is often treated as a writing problem. It is not. It is a risk-control problem.
Firms are now expected to communicate clearly with consumers, not only in marketing materials, but across agreements, privacy notices, product disclosures, website terms, and servicing communications. In financial services, this matters acutely. A document can be legally accurate, technically complete, and still fail in practice because the intended audience cannot understand it well enough to act on it.
That gap between disclosure and comprehension is precisely why intelligibility matters. It also explains why text simplification in regulated environments cannot be reduced to a generic exercise in “rewriting into plain English”.
The rise of large language models (LLMs) has made this distinction more important, not less. General-purpose AI tools such as Microsoft Copilot can produce fluent rewrites quickly and at scale. That makes them attractive to content teams under pressure to simplify complex communications. But speed and fluency are not the same as controlled task execution. In regulated contexts, the question is not whether a tool can produce plausible simpler language. The question is whether it can reduce intelligibility risk without introducing compliance risk.
Our assessment suggests that this is where the systems-level limitations of LLMs like Copilot become visible.
Why simplification matters
Consumers routinely encounter documents that are difficult to interpret, such as credit card agreements, privacy notices, terms of use, and product communications. They all often rely on features such as dense syntax, embedded conditions, legal qualifiers, and low-visibility disclosures. These documents often assume reading stamina, prior knowledge, and confidence with technical vocabulary that many readers do not have.
Where understanding breaks down, risk emerges. Consumers may misunderstand costs, decision points, rights, exclusions, or consequences. In financial services, that has obvious regulatory significance. Under Consumer Duty, firms must not only disclose information, but communicate it in ways that support informed decision-making.
This makes simplification a governed activity. The aim is not merely to make text sound friendlier. It is to reduce comprehension barriers while preserving meaning, required disclosures, and legal fidelity.
The current tool landscape
There are now two broad categories of tools being used for this purpose.
The first category includes general-purpose LLMs and drafting assistants, such as Microsoft Copilot, ChatGPT, Gemini, and Claude. These tools are strong at rapid language generation. They can rewrite text into plainer language, convert prose into FAQs, preserve document structure reasonably well, and generate multiple stylistic alternatives with minimal user effort. Their appeal is obvious: they reduce drafting friction. In this assessment, we tested Microsoft Copilot as a representative example of this category because it is widely available through the Microsoft Office suite and is already commonly used across financial services workflows.
The second category includes specialist intelligibility and simplification tools, such as Amplifi, which are designed around measurement, diagnostics, and controlled improvement rather than generic text generation.
That distinction is central.
About Amplifi
Amplifi is a specialist reg-tech tool designed to assess and improve intelligibility using measurable, objective metrics that aim to predict likely understanding outcomes. It evaluates written information and provides an intelligibility score, an estimated educational equivalent, and reach scores. Its diagnostic workflow identifies structural drivers of complexity so users can intervene where comprehension risk is highest. It also supports continuous reassessment, allowing users to measure whether revisions have improved intelligibility.
Its strengths are methodological. It treats simplification as a measurable process rather than a stylistic one. It has also been tested through academic and regulator-partnered work, which gives it greater relevance in compliance settings.
Its limitations are operational rather than architectural. In particular, it can face formatting-related challenges when dealing with structured content such as tables and numerical formulae in automated scoring and simplification workflows.
About Microsoft Copilot
Microsoft Copilot in Word is a general-purpose generative assistant. It is effective at rewriting text into plain English, maintaining formatting, and quickly creating outputs such as summaries, FAQs, tables, or bulleted steps. In early drafting stages, that capability is genuinely useful.
But Copilot is not a specialist intelligibility system. It does not surface native diagnostics showing why a text is difficult. It does not provide an objective measure of whether a rewrite has materially reduced comprehension risk. It does not verify whether the audience reach of the document has improved. As a result, it can accelerate drafting while shifting the burden of validation and governance back onto the user.
That trade-off becomes critical in regulated workflows.

What we assessed, and how
To assess the two approaches, we compared a widely available generalised LLM, in this case Microsoft Copilot, against Amplifi in the context of simplifying regulated information, specifically consumer-facing financial services documents. We also considered the ability of each tool to support reporting and evidence generation for compliance purposes.
The assessment focused on a typical end-to-end journey:
Initial assessment -> simplification -> reassessment -> reporting
We then evaluated performance across four risk-related layers:
- Intelligibility risk and reach: Did the tool reduce risk and improve likely comprehension, and did it make the drivers of complexity visible?
- Compliance-safe simplification: Did the simplified output preserve semantic fidelity and completeness of disclosure?
- Governance, auditability and scale: Could the tool support prioritisation, consistent target-setting, and evidence suitable for sign-off and reporting?
- User journey and efficiency: Did the tool reduce total effort across each stage of the journey?
To expose behaviour under progressively more realistic constraints, we tested three simplification strategies:
- Paragraph-by-paragraph single-prompt strategy to test baseline capability without prompt engineering
- Hybrid strategy to reflect a more realistic workflow involving diagnosis, targeted prompting, iteration, and validation
- Suggestion-led strategy to test whether the tool could guide editing based on identified complexity rather than user-led prompting alone
The document set included publicly available examples such as:
- Nationwide Credit Card Agreement, minimum payments section
- Ocean Credit Card Agreement, full agreement
- Terms of Use, intellectual property rights section
- Standard Life Privacy Notice, selected sections including profiling and decision-making
- Standard Life press release
- Standard Life funds and charges document, lifestyle profiles section
Key Lessons
We used the three simplification processes using identical prompts across both Amplifi and MS Copilot. This helped us to identify key differences in their approach, the experience of using them, the quality of their outputs, and their overall capability.
Across the examples tested, the most important differences were not stylistic but structural, particularly in how each tool handled task definition, verification, and governance.
This highlights a broader point about the use of AI in regulated communications: success depends not only on the quality of the language produced, but on whether the system can support a controlled, measurable, and defensible process.
The lessons below set out the main implications for organisations seeking to simplify complex information safely and at scale.
1. Simplification is a task, not a rewrite
The central finding is structural and systemic: the limitation is rooted in the system’s architecture, not merely in its performance or outputs.
Text simplification in regulated contexts is not a generic rewriting exercise. It is a task-based objective with fixed constraints: reduce intelligibility risk, preserve legal meaning, retain required disclosures, and avoid adding ambiguity or new commitments. A suitable system must therefore do more than generate language. It must understand the task boundary, execute within it, and provide a way to verify completion.
This is where Copilot and Amplifi diverge most sharply.
Copilot is designed to produce plausible language outputs in response to prompts. That is useful, but it is not the same thing as task completion. Amplifi, by contrast, approaches simplification as a measurable and bounded process. The task is defined in advance, guided by diagnostics, and evaluated through scoring. Human intervention remains important, but it is supported by an explicit control structure.
That systemic difference explains why Copilot can appear effective on first reading while proving fragile under scrutiny.
2. The core systems issue: generative versus task-oriented architecture
At its core, Copilot is a probabilistic text generator. It predicts likely language continuations from prompts. This architecture is well suited to drafting support, but it does not inherently guarantee that a defined simplification task has been completed correctly.
A task-oriented simplification system needs four things:
- a clear task definition
- controlled execution within scope
- measurable success criteria
- verifiable completion
Copilot does not natively provide any of these in a robust, surfaced way. It can follow instructions, but it does not enforce them as hard constraints. It can produce a fluent simplified version, but fluency is not evidence of fidelity, completeness, or reduced risk.
Amplifi is a task-based system because it is built around those four requirements. The task is defined as reducing intelligibility risk while preserving meaning. Diagnostics identify where complexity resides. Progress can be measured. Outcomes can be evidenced.
That difference is foundational, not cosmetic.
3. Prompt engineering is not a substitute for system control
In Copilot, prompt engineering functions as a workaround for missing control architecture. Users must express the task requirements in natural language, often combining instructions such as:
- simplify this text
- reduce sentence length
- preserve defined terms
- retain formatting
- do not omit disclosures
This creates three problems.
First, prompts are not enforceable constraints. Because they are interpreted probabilistically, the model may follow them fully, partially, inconsistently, or not at all.
Second, regulated simplification typically requires several objectives to be held at once. As prompt complexity increases, reliability often falls. The user ends up balancing clarity of instruction against execution fidelity.
Third, outcomes become highly dependent on user skill. Better prompt writers may get better results, but that is not a sound basis for operational consistency across teams.
Amplifi reduces this dependency by shifting control into the workflow itself. Complexity is diagnosed before rewriting. Targets are visible. Improvement is measured after intervention. Prompts, where used, exist within a governed structure rather than acting as the sole mechanism of control.
4. Copilot lacks stable task understanding
A deeper limitation is that Copilot does not reliably know whether it has understood the task correctly. It produces outputs that appear responsive to intent, but it has no internal representation of task success in the regulatory sense.
That creates predictable failure modes:
- expanding beyond the requested scope
- dropping or softening legal qualifiers
- oversimplifying through omission
- applying changes inconsistently across sections
These are not edge cases. They follow directly from a system that interprets intent through language generation rather than executing a bounded process.
Amplifi mitigates this by anchoring the task in measurable intelligibility reduction. The system identifies where risk sits, supports targeted intervention, and shows whether that intervention improved the score. The task is therefore less dependent on inferred intent and more closely aligned to explicit criteria.
5.Verification is the missing layer
One of the most significant limitations of Copilot is the absence of built-in verification.
After generating a simplified output, Copilot does not independently confirm that intelligibility has actually improved. It may generate a self-assessment, but that is not independent validation and should not be treated as such.
This is the central risk of using a generative assistant as though it were a task-completion system. Fluent output can create the impression that the work is done when, in fact, the critical verification stage has simply been outsourced to the human reviewer.
Amplifi does not solve semantic verification completely, but it does introduce a real validation framework. Users can compare baseline and post-edit scores, review complexity drivers, and judge whether measurable improvement has occurred. That substantially lowers the risk of invisible failure.
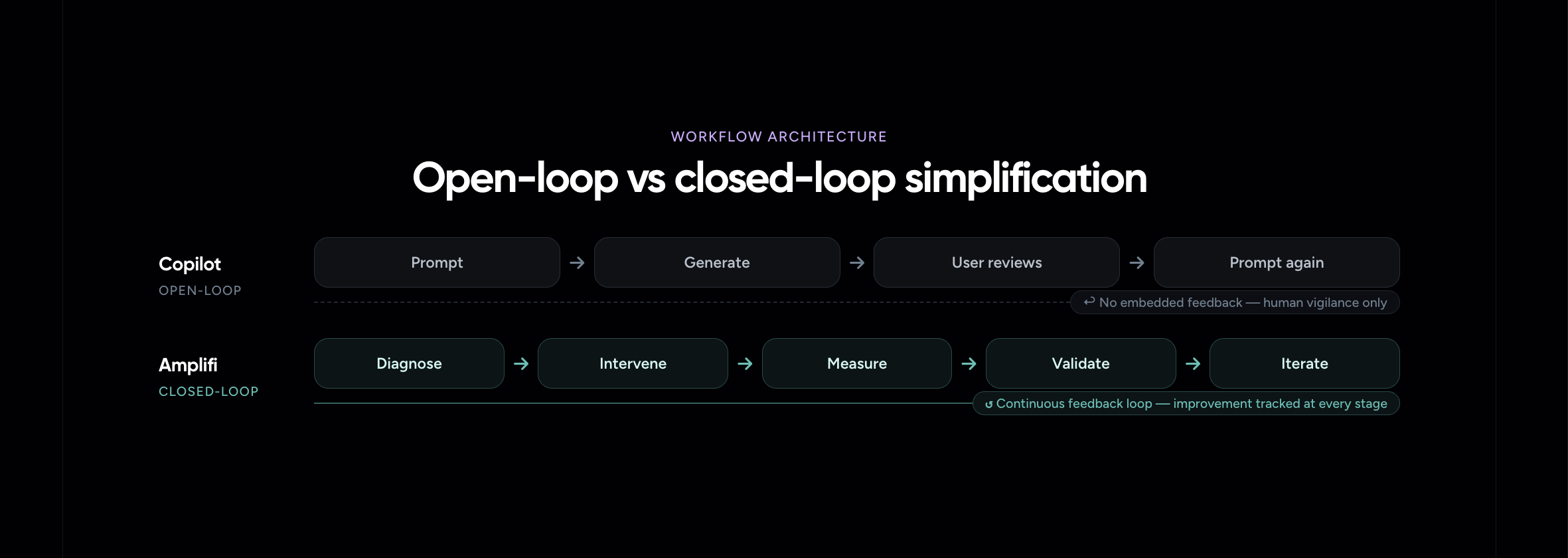
Open-loop versus closed-loop workflows
The workflow difference can be expressed simply.
Copilot typically operates as an open-loop system:
Prompt -> generate -> user reviews -> prompt again
There is no embedded feedback mechanism tying each output back to the objective. Improvement is not inherently tracked.
Amplifi is much closer to a closed-loop system:
Diagnose -> intervene -> measure -> validate -> iterate
That matters because closed-loop systems reduce uncertainty. They create continuity between iterations and support cumulative improvement. Open-loop systems, by contrast, depend heavily on human vigilance and introduce greater variability in both quality and effort.
Reproducibility, governance, and auditability
In regulated settings, a simplification process must be repeatable, explainable, and defensible. This is where Copilot’s strengths in drafting become weaknesses in governance.
Because it is generative, the same prompt can produce different outputs across repeated runs. Small changes in wording or document context can produce disproportionate changes in result. That variability may be tolerable in creative tasks. It is far less acceptable in compliance-sensitive workflows.
Copilot also does not natively provide a governance trail of the kind firms need: baseline measures, explicit diagnostics, structured evidence of improvement, or a consistent record suitable for sign-off and regulatory reporting. Those artefacts must be reconstructed externally.
Amplifi is materially stronger here.
It provides baseline and final intelligibility scores, visibility into drivers of complexity, and evidence that supports defensible decision-making. Even where manual review remains necessary, the process is more transparent and more scalable.
What this means in practice
The issue is not that Copilot writes badly. In many cases, it writes very well. The issue is that good language generation is not the same as reliable task execution.
For regulated simplification, Copilot is best understood as an assistive drafting aid, not a stand-alone system of control or validation. It can help generate first-pass rewrites, alternative phrasings, summaries, and structured outputs. But it does not provide the control architecture required to ensure that simplification has been completed safely, consistently, and evidentially.
Amplifi is better aligned to that requirement because it is designed to manage intelligibility risk rather than merely rephrase text.
.png)
Conclusion
At a systems level, Copilot is not the right tool to rely on for task-based simplification in legal or regulated environments, not because it lacks linguistic fluency, but because it lacks the architecture required for bounded execution, verification, and governance.
Its limitations are systemic and structural:
- dependence on prompt engineering rather than embedded controls
- no native verification of task completion
- no objective success criteria for intelligibility improvement
- open-loop workflow with weak feedback
- limited reproducibility
- weak auditability and governance support
Amplifi addresses these limitations more directly through diagnostics, measurable scoring, structured workflows, feedback loops, and governance artefacts. It is therefore better suited to organisations that need simplification to function as a controlled compliance process rather than an informal drafting exercise.
The real distinction between these tools is not simply one of performance. It is one of design philosophy.
Copilot is built to generate language.
Amplifi is built to manage and reduce intelligibility risk.
In regulated simplification, that distinction is decisive.

Explore more articles








